사내 프로젝트로, 네이버 클라우드 플랫폼의 수많은 사용자 가이드에 대해 대응할 수 있는 AI 챗봇을 개발중이다.
AI 개발에서 필수적인 과정은 학습 데이터를 수집하는 과정이다. 따라서 네이버 클라우드의 사용자, API, CLI 가이드 의 내용을 모두 수집할 수 있는 bot 을 만들기로 결정하고 진행했다.
대략 1만개가 넘는 엄청난 숫자의 페이지였는데, 이것을 사람 손으로 일일히 수집하기란 어마어마한 수고가 들 수 밖에 없다. 또한, 새로운 데이터가 업데이트 되었을 때도 사람 손으로 데이터를 수정하기란 쉽지 않은 일이다. 결과적으로는 이 bot으로 데이터셋을 관리함으로써 큰 도움이 되었다.
구현에는 Python 을 사용했고, Playwright와 BeautifulSoup 라이브러리를 활용했다.
구현 과정
네이버 클라우드의 사용자 가이드는 보안 설정이 되어 있어, 일반적인 크롤러 프로그램으로는 수집이 안 된다. 따라서, 실제 사용자의 브라우저 환경을 그대로 띄워서 수집할 수 밖에 없다. 사람 손으로 노가다 하느냐, 컴퓨터가 노가다 하느냐의 차이라고 볼 수 있겠다.
우선, 데이터셋을 결정해야 한다. AI 의 데이터셋은 학습시킬 데이터마다 매우 다르고, 고민이 많이 되어야 할 부분으로 각자 수행중인 프로젝트 마다 큰 차이가 있을 것이다.

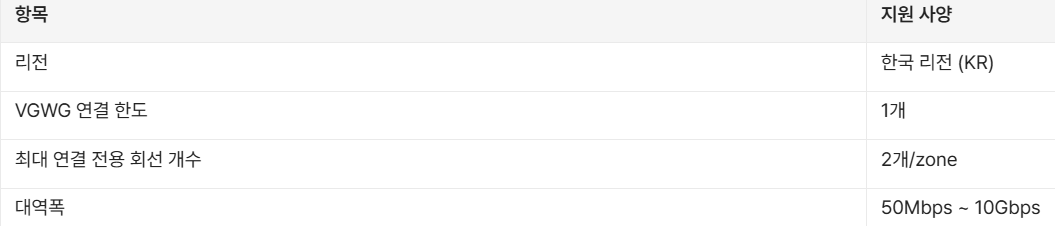
진행 중인 프로젝트에서는 위와 같다.
idx : index 넘버
작업자 : 작업자명
주소 : url
서비스명 : 크롤링을 수행할 서비스명
좌측 메뉴 상의 상하위 관계 :
<< 이 부분이다. 카테고리 데이터가 있어야 AI가 이해하기 쉽기 때문에 필수 값이다.
페이지 내의 상하위 관계 :
<< 가이드 문서 내 소제목에 해당한다.
내용 : 본문 내용
네이버 클라우드 사용자 가이드의 페이지에서 개발자 콘솔을 통해 [요소] 를 확인하여 뽑아내야 할 부분을 추출했다.
추출해야 할 부분은 다음과 같다. 사이드바와 본문의 내용이다.
여기서 실제 값들이 위치한 요소들의 값을 따와 이 부분을 크롤링 수행하도록 코드를 작성했다.
예를 들면 이런 식이다.
<< <h2> 값으로 소제목을 구분
이 때, 크롤러가 각 소제목을 어떻게 구분하느냐?
▲목차 부분의 요소를 긁어와 구분할 수 있도록 했다.
대략 이런 식으로 각 페이지 내 요소들을 구분짓고, 어느 부분을 가져와야 할 지 크롤러에게 기준을 명확히 세워두었다. 조금 더 구체적으로 보자면, 표를 인식하게 되면 markdown 으로 변환할 수 있도록 하는 기능도 넣었다.

각 내용의 추출은 BeatifulSoup 라이브러리가 담당한다. 또한, 각 카테고리를 구분하기 위해서 Breadcrumb 을 활용했다.
좌측 left_sidebar 기준으로 메뉴 상하위 구조를 크롤러가 파악한 뒤, < 좌측 메뉴 상의 상하위 관계 > 부분에 파악한 카테고리 구조를 기입해 넣는다.
구체적인 코드는 외부 공개가 불가하지만, 대략 이런 구조로 되어 있다면 개발자라면 어떻게 만들었는지 알 수 있을 것이라 생각한다.
프로그램 구현 & 실행
파이썬 코드를 모두 작성한 상태에서, 추가적으로 팀 내에서 사용할 수 있도록 GUI 형태로 빌드하였다.
어차피 UI 신경쓸 것은 아니니 Tkinter 를 통해 간단하게만 만들었다. 가능한 빌드된 파일의 용량을 줄이고, 패키징 안정성을 높이기 위해 Playwright 가 로컬 PC에 설치된 브라우저를 사용할 수 있게끔 개선했다.
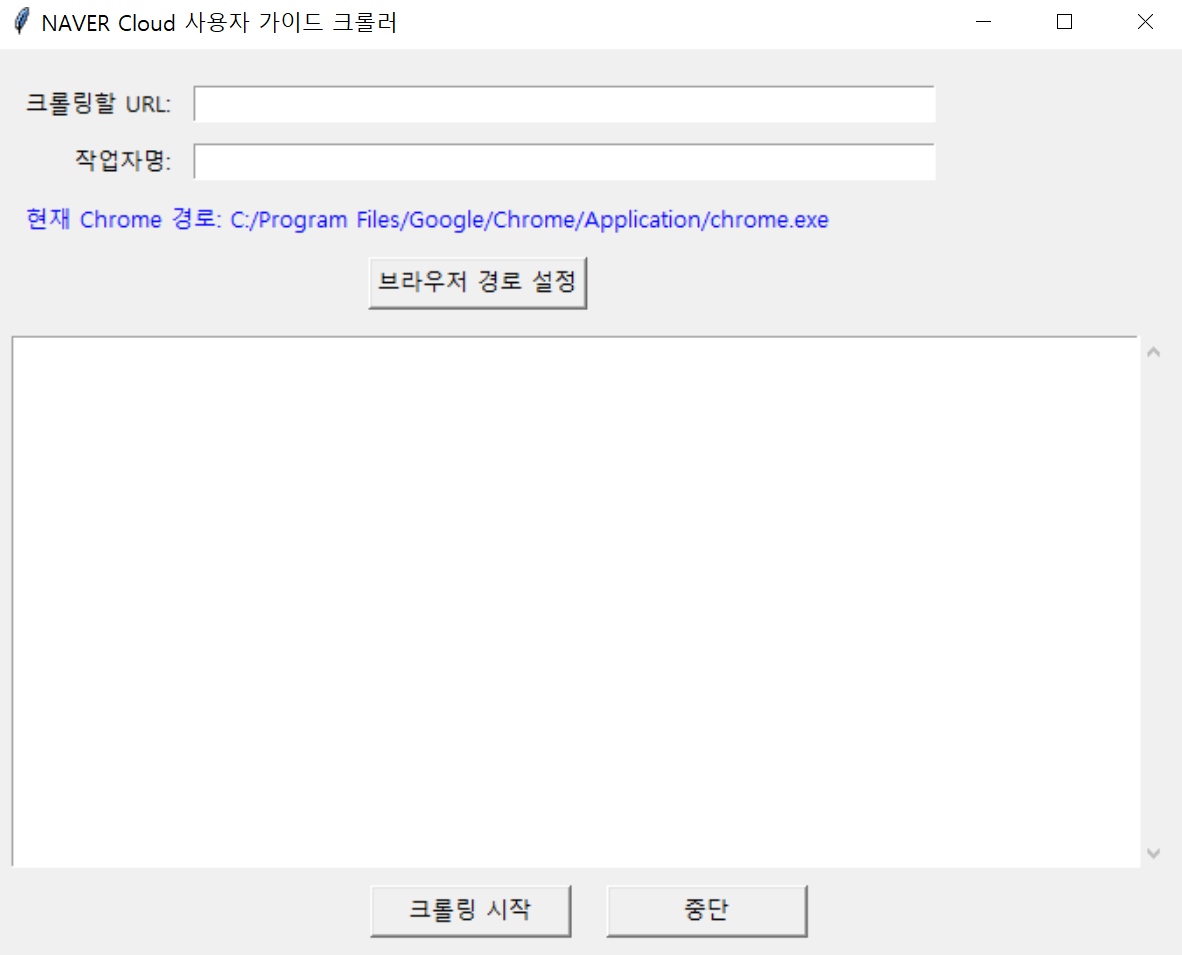
결과적으로는 이런 형태가 된다. 크롤링할 서비스의 URL 을 넣고 작업자명을 넣은 뒤 시작하면 자동으로 Playwright 가 로컬 PC 내 브라우저를 실행시켜 접근하고 크롤링을 시작한다.
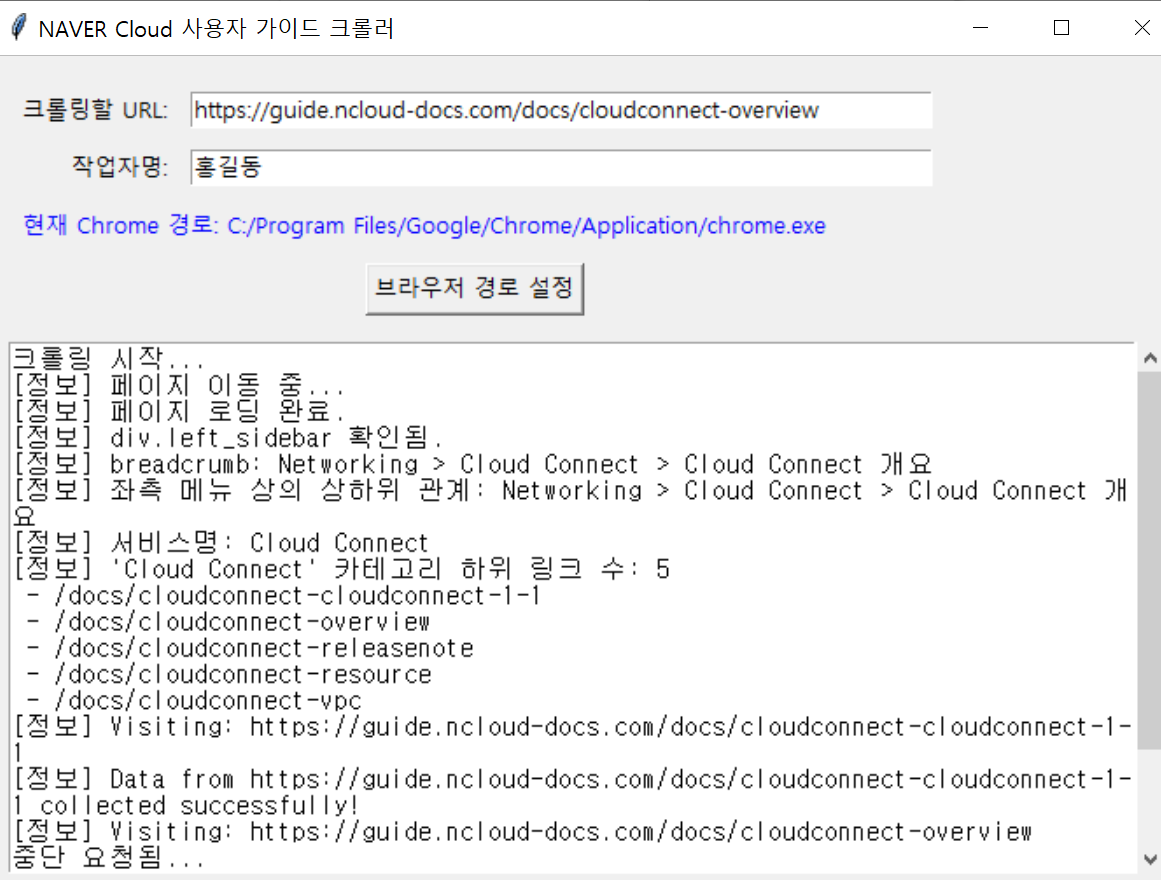
자동으로 브라우저가 로드되고, 긁어오는 과정을 보여준다. 완료되면 엑셀 파일로 데이터셋을 저장한다.

파이썬 파일 코딩이 완료되어, 최종 사용자에게 배포하기 위해 pyinstaller 를 사용해 빌드를 진행했다.
pyinstaller --onefile --noconsole --upx-dir="~~" crowling_NCP.py
사용하기 쉽도록 onefile 로 빌드하고 콘솔 노출을 없앴으며 upx를 사용해 용량을 최대한 줄여봤다. 하지만 그래도 최종 배포 파일의 용량은 180MB 정도가 나왔는데, 이는 Playwright 의 무지막지한 용량 때문에 줄일 수가 없는 듯하다. 더 줄일 방법이야 없진 않겠지만 굳이 그러진 않았다. 그 시간에 다른 작업을 하는게 이득..
이렇게 배포까지 마쳤다. 대략 3일 정도 걸린 듯하다. 업무 짬짬히 만들었는데 덕분에 시간 잘 가고 좋았다.
그리 어려운 작업은 아니었는데, 간만에 자동화 프로그램 만들다 보니 조금 재밌었던 것 같다.
결과적으로 이 프로그램을 통해 AI 봇 개발 및 유지보수에 꽤 많은 도움이 될 것으로 보여져, 프로젝트에 기여할 수 있을 것으로 예상된다.
'IT > NAVER Cloud Platform' 카테고리의 다른 글
| [CLOVA Studio] Skill Trainer 를 활용한 RAG 모델 구현하기 (1) | 2024.12.22 |
|---|---|
| [CLOVA Studio - 2] 스킬 트레이너 활용하기 (0) | 2024.04.14 |
| [CLOVA Studio - 1] Prompt Programming (0) | 2024.03.23 |
| [NAVER Cloud Platform] Kubernetes Service 구성하기 (1) | 2023.04.22 |
| [NAVER Cloud Platform] VOD Station 서비스 맛보기 (0) | 2023.03.07 |