최근 프로젝트를 통해서 RAG 모델을 구축 진행해보았다. 목적은 네이버 클라우드의 사용자 가이드를 취합해 답변하는 bot 을 생성하는 것으로, 모두 네이버 클라우드의 인프라로만 구축하였다. 본 포스팅의 목적은 생각보다 데이터베이스를 읽어오는 챗봇의 구성은 그리 어렵지 않다는 것을 소개하고 싶다.
본 과정에서 아무래도 가장 어려운것은 데이터 정제 과정이라고 생각된다.
Studio Chatbot Architecture
아키텍처의 구성도는 대략 다음과 같다.
API Server : Cloud Functions
Web Server : Apache
Database : Excel, Object Storage
AI : CLOVA Studio
Embedding : CLOVA Studio Embedding API
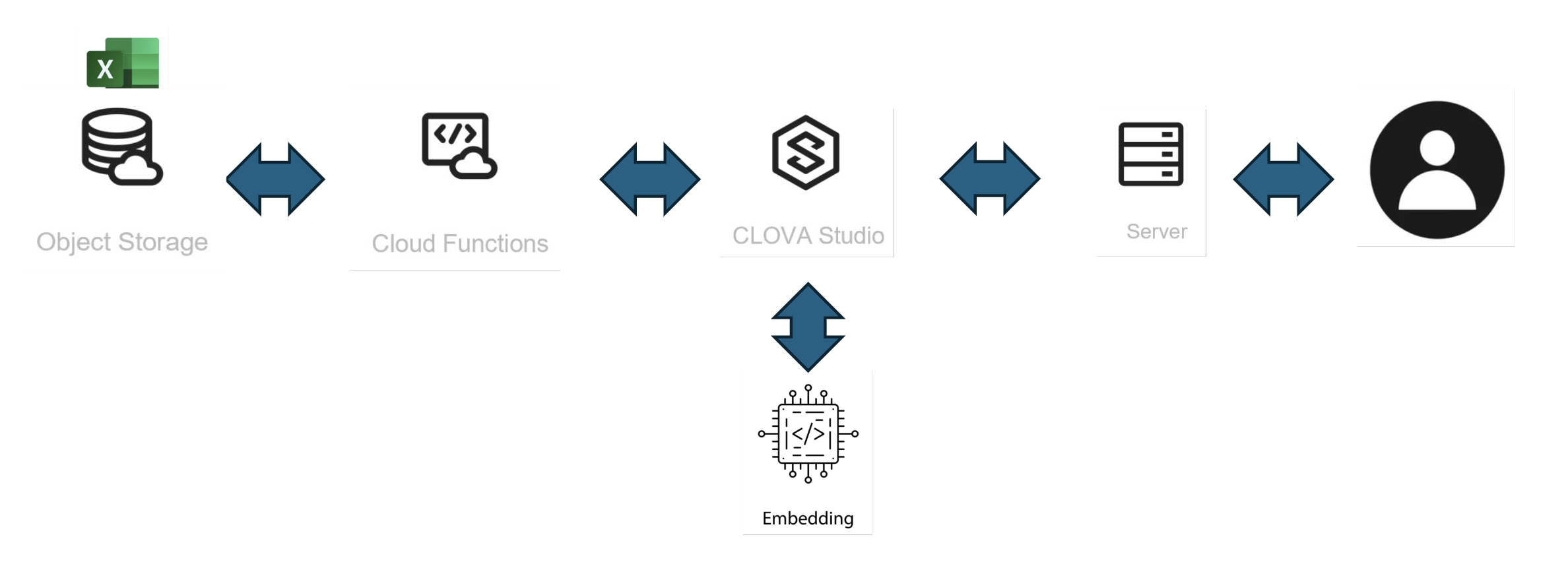
구성이 어렵지는 않다. RAG 모델을 만드는 것이 그리 어렵지 않다는 것을 이 포스팅을 통해서 소개하고 싶다.
내부 구성은 대략 다음과 같다.
1. DB : 쿼리가 필요하지 않은 액셀로만 정리했으며 미리 네이버 클라우드 플랫폼의 사용자 가이드 내용을 임베딩화 하여 넣어두었다.
2. Cloud Functions : 액셀 데이터를 읽어와 Studio 로부터 넘겨받은 임베딩 된 질의값 중 top 5를 선정해 Studio 에게 json 으로 리턴한다.
3. Embedding API : CLOVA Studio 의 임베딩 API 를 사용했다. 프로젝트 진행 중 여러 다른 자체 API 들도 테스트 해보았지만, 결론적으로는 사용하기 편리한 Studio API 를 선택했다.
4. CLOVA Studio : Studio 는 User의 질문사항을 Embedding API 를 호출해 변환하고, Cloud Functions 에게 데이터를 토스한 뒤 리턴받은 top 5 데이터값 중 고객이 질문한 내용과 가장 가까운 내용을 정리해 답변하도록 세팅한다. CLOVA Studio 의 [스킬 트레이너] 를 활용한다.
5. Object Storage : 각 서비스별로 Excel 파일을 구분하여 저장
6. Server : Apache Web Server 구성
이상이 대략적인 구상도이다. 구성도로만 봐도 정말 간단하고 어렵지 않다.
진행 과정
1. 데이터 정제 과정
RAG 모델을 구성할 때, 가장 많이 작업해야되고 가장 손이 많이가는 부분은 역시 "데이터" 이다.
당연하겠지만 빠른 응답이 필요한 모델이라면, MySQL 과 같은 관계형 DB를 사용하여야 겠지만 테스트 및 빡센 작업을 요구하는 모델을 작업하는 것이 아니었기에 데이터 관리 및 접근성이 비교적 용이한 Excel 로 작업하였다.
Excel 파일의 컬럼은 다음과 같이 세팅한다.
Key / Title / Value / Embedding Value
예를 들어, 아래 사용 가이드라면 값은 다음과 같이 세팅될 것이다.
Key : 1
Title : 서버 사양
Value
서버를 생성하기 전에 네이버 클라우드 플랫폼에서 제공하는 서버 타입 및 서버 이미지를 먼저 확인해 주십시오.
네이버 클라우드 플랫폼에서는 1세대부터 3세대까지의 서버를 제공합니다.
- 1세대(g1) 서버: 서비스 최초 제공 시 개발된 버전입니다. XEN 하이퍼바이저 기반의 서버로 HDD, SSD 타입의 스토리지를 사용할 수 있습니다.
- 2세대(g2) 서버: 1세대 서버 대비 CPU와 네트워크 등에서 성능이 개선되고 안정성이 향상된 버전입니다. XEN 하이퍼바이저 기반의 서버로 HDD, SSD 타입의 스토리지를 사용할 수 있습니다.
- 3세대(g3) 서버: 기존 서버보다 더 나은 성능을 위해 도입된 KVM 하이퍼바이저 기반의 서버입니다. 기존의 1, 2세대 서버 대비 서버, 스토리지, 스냅샷, 서버 이미지의 호환성이 구분되며, FB1(Fixed Block Storage), CB1(Common Block Storage) 타입의 스토리지를 사용할 수 있습니다.
- 하이퍼바이저가 다른 리소스는 서로 호환되지 않습니다.
- 3세대 서버는 현재 한국, 싱가포르, 일본 리전에서만 지원됩니다.
Embedding Value : Value 값을 1차로 요약한 뒤, 요약된 값을 다시 Embedding 한다. 요약과 임베딩 모두 Studio API 를 사용한다. 여기서는 다루지 않는다.
아무래도 데이터 정제 작업이 가장 수고스러울 수 밖에 없다. 사용 가이드의 내용을 모두 수집해야 하는 노가다가 필요하다. url 을 던져주면 읽어와 학습하는 기능이 있었으면 이런 과정은 필요치 않을 것이다.
자, 이렇게 데이터가 준비되었다면 Object Storage 에 업로드해 저장한다.

저장된 이 파일을 Cloud Functions 에서 읽어와야 한다. 즉, 다음 과정은 API Server 구축이다.
2. API Server 구축 (서버리스)
API Server 를 위해 따로 서버를 또 두는 것이 일반적이긴 하지만, 내가 이번에 작업하는 구성도는 그리 많은 리소스를 요구하지 않고 단순 반복 작업만을 할 뿐이기에, 비용 절감 및 효율적인 리소스 활용을 위해 서버리스 서비스인 Cloud Functions 을 사용한다.
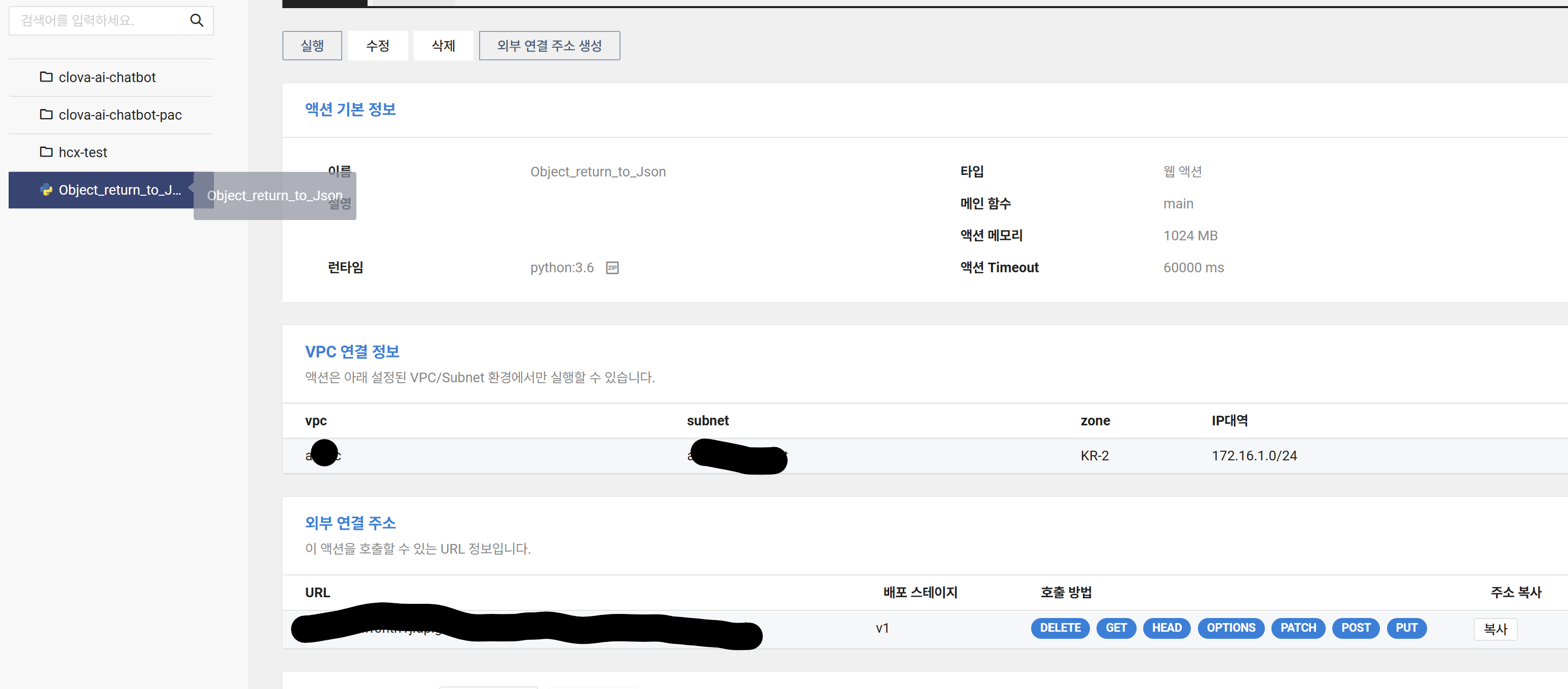

실행하면 json 타입으로 선별된 데이터를 리턴하도록 구성한다. 코드는 외부 공개가 불가능하지만, 이 코드 GPT한테 물어보면 정말 잘 알려주니 능력껏 구현해보자.
이제, CLOVA Studio 가 이 API 를 불러올 수 있도록 설정해야 한다. 이를 위해서는 API Gateway 서비스와의 연동이 필요하다. REST 방식의 API 가 서로 데이터를 주고 받을 수 있도록.

API Gateway 서비스에서 Target 을 Cloud Functions 으로 지정한다. 이제 이 Invoke URL 을 통해 외부에서 이 API 를 호출할 수 있게 되었다.
3. CLOVA Studio - Skill Trainer 구성하기
Skill Trainer 기능은 이 아키텍처에서의 핵심이다.
사용 가이드를 먼저 참고하여 이해하는 것이 우선으로, ChatGPT 에서도 비슷한 기능을 제공 중에 있다.
GPT Plus 구독하면 사용할 수 있는 기능 중, OpenAPI Spec 을 입력해 외부 API 와 연동할 수 있도록 하는데, 이것이 그것과 같다.

GPT 편집 부분 들어가보면 [작업] 부분에서 이 부분을 확인해볼 수 있다.


OpenAPI Spec 작성은, 간단하게 말하자면 위에서 작성한 API 를 어떻게 호출해야되는지? 를 기재해두는 json 형식의 기술 문서라고 볼 수 있다.
Manifest 부분은 Studio AI 모델이 이 API 를 활용하는 방법을 가르쳐주는 부분이라고 이해하고 작성한다.
'IT > NAVER Cloud Platform' 카테고리의 다른 글
| [CLOVA Studio - 2] 스킬 트레이너 활용하기 (0) | 2024.04.14 |
|---|---|
| [CLOVA Studio - 1] Prompt Programming (0) | 2024.03.23 |
| [NAVER Cloud Platform] Kubernetes Service 구성하기 (1) | 2023.04.22 |
| [NAVER Cloud Platform] VOD Station 서비스 맛보기 (0) | 2023.03.07 |
| CDN / GRM 정리 및 간단 실습 (0) | 2022.08.06 |